15618 Project: Fibonacci Heap in Parallel
Milestone Report: Parallel Fibonacci Heap
Authors: Lemin Zhang, Zihao Du
Current Progress
So far, we have largely followed the schedule proposed in our project plan and made substantial progress during the first two weeks. At this stage, we have completed the core groundwork needed to build a parallel Fibonacci heap and have begun exploring different parallelization strategies.
-
Serial Implementation. We first read the related literature, studied the design principles of Fibonacci heaps, and implemented a basic serial version in C++. Our implementation supports the core operations: insert, deleteMin, and decreaseKey. We also wrote simple smoke tests to verify the correctness of the implementation.
-
Coarse-Grained Locking Version. Based on the serial implementation, we implemented a thread-safe version of the Fibonacci heap in which all public operations are protected by a single coarse-grained lock.
-
Benchmarking Infrastructure. We designed benchmark cases for the baseline Fibonacci heap and also prepared a binary heap implementation for comparison. We built a workload generator that produces random but legal traces, where the relative frequencies of the three operations can be configured by the user. We also evaluated the data structure under different thread counts and different workload sizes. To analyze performance, we measure execution time, throughput, and cache-miss-related behavior under different test settings, and visualize the results for easier comparison and interpretation.
Overall, we think the project is on the right track. As described in our proposed schedule, the next step is to continue exploring semantic relaxation in Fibonacci heaps and apply these ideas to parallelization. We are currently working on the parallelization of insertion. However, our preliminary results show that the overhead introduced by parallelization can outweigh the potential speedup, leading to lower throughput instead of improvement. This suggests that we need to further analyze the costs and benefits of different synchronization strategies and identify a design that better fits the structure of the Fibonacci heap.
Goals and Deliverables
We are generally following our proposed schedule and have completed the first major milestone. At this point, we do not anticipate significant changes to our overall final goals. However, during implementation and evaluation, we found that building a fine-grained parallel Fibonacci heap without semantic relaxation is not a meaningful direction. Although it is possible to replace a single coarse-grained lock with multiple finer-grained locks, the global minimum remains a fundamental bottleneck. Without relaxing the semantics of \texttt{deleteMin}, we do not expect fine-grained locking alone to provide substantial performance improvement. Therefore, we decided to skip this intermediate version and move directly from the coarse-grained implementation to a parallel design with semantic relaxation.
In addition, the design of the benchmarking infrastructure took more time than we originally expected. In particular, we spent lots of time implementing random but legal operation traces and building a usable experimental framework. As a result, we no longer plan to pursue the ``nice-to-have’’ features unless we finish the main project goals earlier than expected.
We restate the goals we plan to complete below:
- Implement a correct baseline Fibonacci heap.
- Implement a parallel Fibonacci heap with semantic relaxation.
- Run experiments on the GHC machines to evaluate the performance of the best parallel version under workloads with different characteristics.
- Explore dynamic task scheduling on heterogeneous CPUs.
Poster Session
For the poster session, we plan to prepare a poster that includes the following:
- A brief introduction to the Fibonacci heap and the asymptotic time complexity of its core operations.
- Pseudocode and visual illustrations of our parallel implementations.
- Benchmark configurations and experimental results, including speedup graphs as functions of the number of operations, the number of threads, and workload characteristics.
Preliminary Results
At this stage, we have conducted experiments on both the coarse-grained Fibonacci heap and the binary heap. We evaluated the two data structures under three operation-set sizes (10K, 100K, and 1M), three workload characteristics (equal insert/delete, half insert with the remainder split between delete and decrease-key, and mostly insert with only a small fraction of delete and decrease-key), and four thread counts (2, 4, 8, and 16). We ran all experiments on the GHC machines and obtained the following results:
-
Coarse Lock Limits throughput. We found that throughput does not increase as the number of threads grows, because all threads contend for the same global lock.
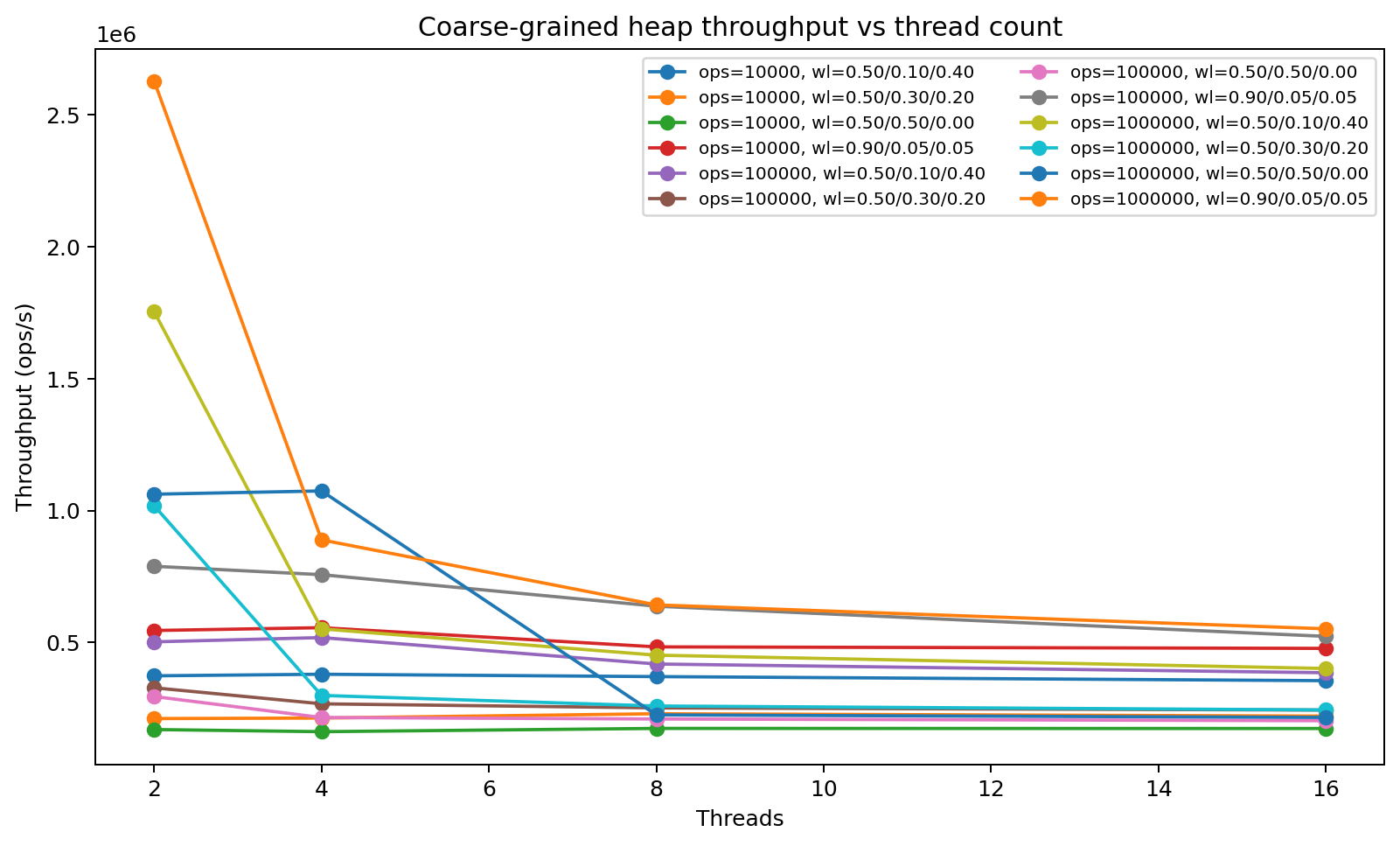
Throughput vs Thread Count. -
Fibonacci Heap is less cache friendly. As expected, the Fibonacci heap is implemented with nodes and pointers, which leads to poor spatial locality. As a result, it incurs a higher cache miss rate than the binary heap.
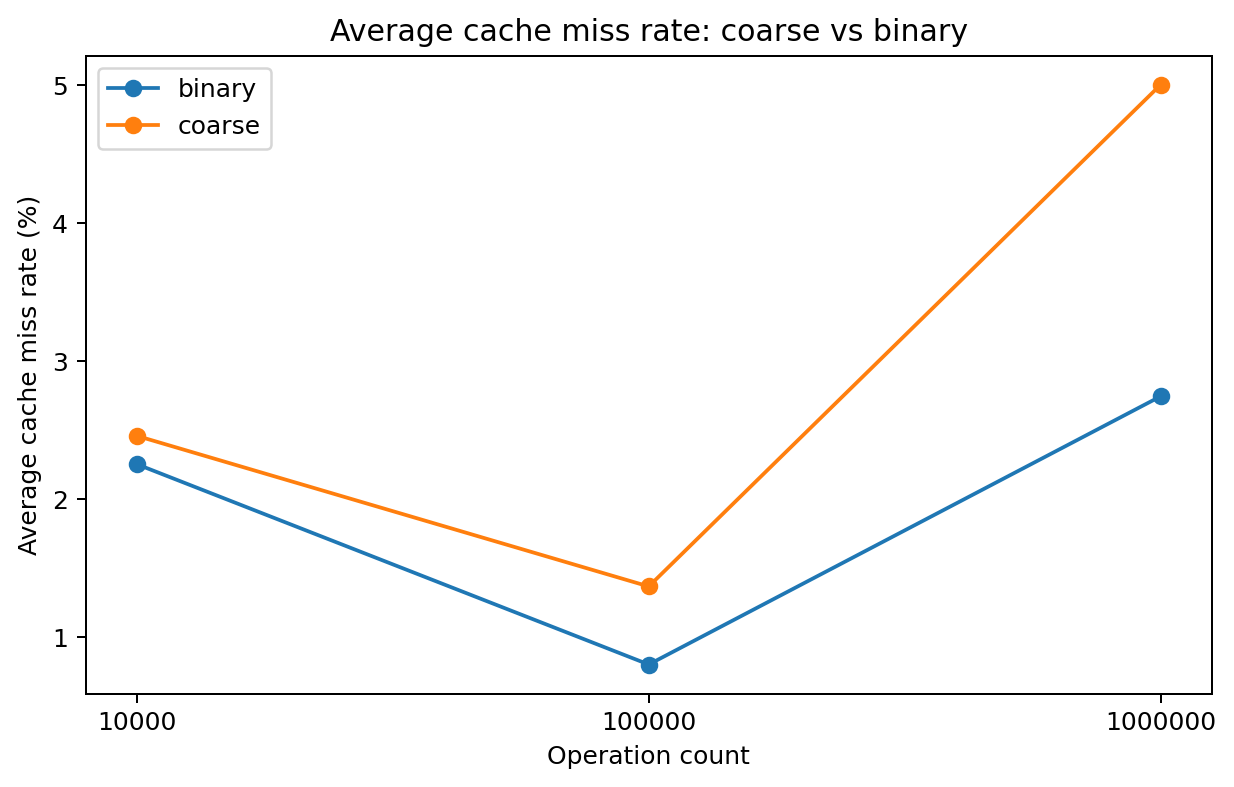
Cache miss rate. -
DeleteMin is the bottleneck. We observe that throughput is higher when the workload is dominated by insertions or decrease-key operations. This is consistent with the theoretical time-complexity analysis, since \texttt{DeleteMin} is the most expensive operation in the Fibonacci heap.
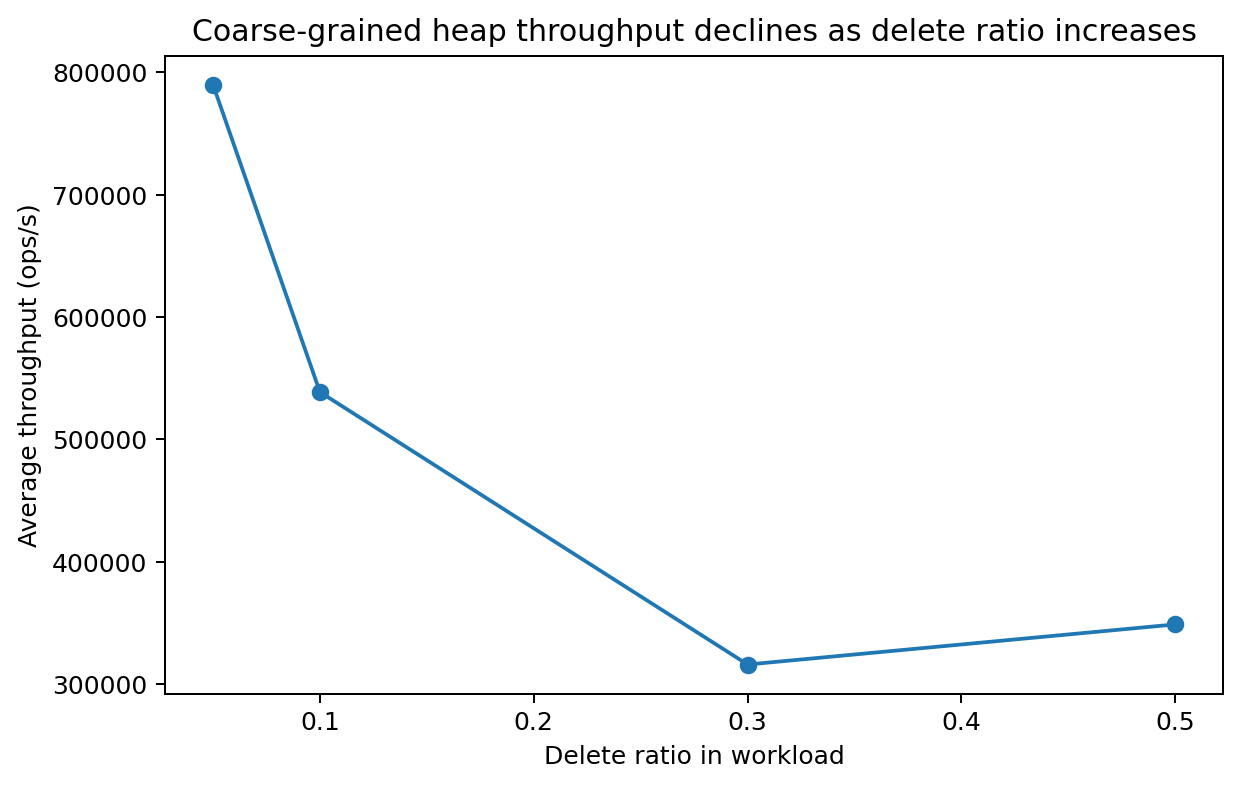
Throughput vs DeleteMin ops Count.
Issues
While we have made steady progress on the serial baseline, the coarse-grained version, and the benchmarking framework, several concerns remain that we are actively addressing:
- High Overhead May Outweigh Parallel Speedup. Our biggest concern is that the overhead introduced by parallel synchronization may outweigh its theoretical benefits in practice. In our current attempts, adding multiple synchronization points, extra metadata, and more complex coordination mechanisms often substantially increases constant factors. For operations such as insertion, the cost of lock acquisition, retry behavior, and shared-state updates can dominate the useful work itself. As a result, some of our fine-grained designs have shown lower throughput than the coarse-grained baseline, even in insert-heavy workloads where we initially expected greater parallel benefit.
- The Complexity of Benchmarking Legal Concurrent Traces. Designing a meaningful benchmark has proven more difficult than expected. Since heap operations have dependencies, especially when \texttt{decreaseKey} is involved, generating random yet still legal traces requires additional constraints and bookkeeping. We want workloads that are both representative and experimentally fair, while also avoiding invalid operations that would artificially distort the results. Balancing realism, legality, and implementation simplicity in the benchmark generator remains an ongoing challenge.
At this stage, the remaining work is not only about building theoretically well performed parallel strategies, but also about resolving these design questions and achieving practical speedup.